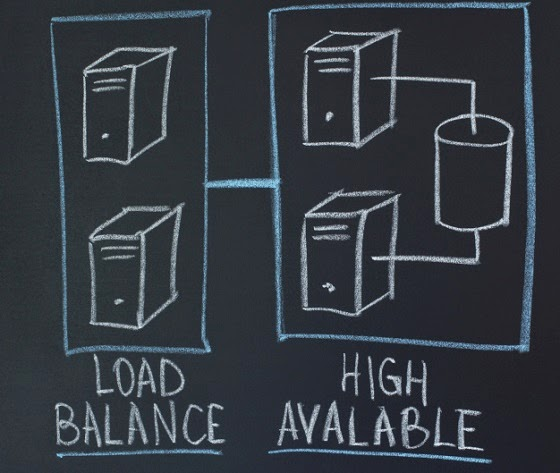
Keepalived is a Linux implementation of the VRRP (Virtual Router Redundancy Protocol) protocol to make IPs highly available – a so called VIP (Virtual IP).
Usually the VRRP protocol ensures that one of participating nodes is
master. The backup node(s) listens for multicast packets from a node
with a higher priority. If the backup node fails to receive VRRP
advertisements for a period longer than three times of the
advertisement timer, the backup node takes the master state and
assigns the configured IP(s) to itself. In case there are more than
one backup nodes with the same priority, the one with the highest IP
wins the election.
I have ditched Corosync + Pacemaker for simpler and easily manageable cluster via Keepalived. Any of you who have played with Pacemaker will understand what I mean. I assume you’ve already got your Kamailio server installed and configured.
Install Packages
I am using Ubuntu server for the installation.
apt-get install -y keepalived sipsaksipsak here will be wrapped in a check script to ensure Kamailio is still accepting SIP quests. VRRP is good for detecting network failure, but we also need something in place to check on the service level.
Set Kamailio to listen on VIP
Allow Kamailio to bind or listen to the VIP even when the VIP does not exist on the backup node. You first need to append the following to /etc/sysctl.conf
# allow services to bind to the virtual ip even when this server is the passive machine
net.ipv4.ip_nonlocal_bind = 1Enable the setting immediately:
sysctl -pChange Kamailio’s config file /etc/Kamailio/Kamailio.cfg to force Kamailio to listen on the VIP:
listen=<<VIP>>:<<Port Num>>Apply the above to both severs, and restart Kamailio:
service Kamailio restartConfigure Keepalived
Create /etc/keepalived/keepalived.conf with the following content on both nodes
!Configuration File for keepalived
vrrp_script check_sip {
script "/etc/keepalived/checksip.sh"
interval 5 # check every 5 seconds
fall 2 # require 2 failures for KO
rise 4 # require 4 successes for OK
}
vrrp_instance SBC_1 {
state BACKUP
interface eth0
virtual_router_id 56
# priority 100
nopreempt
advert_int 1
authentication {
auth_type PASS
auth_pass somepassword
}
virtual_ipaddress {
123.123.123.123/24 brd 123.123.123.255 dev eth0 label eth0:0
}
track_script {
check_sip
}
notify_master "/etc/keepalived/master-backup.sh MASTER"
notify_backup "/etc/keepalived/master-backup.sh BACKUP"
notify_fault "/etc/keepalived/master-backup.sh FAULT"
}- If you have multiple pair of Keepalived cluster running on the same subnet, make sure each pair’s
vrrp_instancename andvirtual_router_idnumber are different or else the failover will not work correctly. - Comment out the
priorityso that the VIP won’t flap when a failed node comes back online. In other words, make the VIP sticky to the node it’s currently running on. - Change the
fallandriseinterval under thevrrp_script check_sipaccording to your need. Once the script determined that Kamailio is down, Keepalived will failover the VIP to the backup server. - Notification parameters at the bottom of the configuration:
- notify_master – will be triggered on the server that is becoming the master server.
- notify_backup – will be triggered on the server that is degraded to be a backup server or starting up as a backup server.
- notify_faults – will be triggered when any of the vrrp check script reached it’s threshold and determines the service is no longer available, then the status will turn into faults and trigger the notify_faults script.
Apply the same configuration file on both the master and backup nodes.
Create Checking Script
There is no fencing mechanism available for Keepalived. If two participating nodes don’t see each other, both will have the master state and both will carry the same IP(s). When I was looking for a way to detect which one should stay the master or give up his master state, I discovered the Check Script mechanism.
A check script is a script written in the language of your choice which is executed regularly. This script needs to have a return value:
- 0 for “everything is fine”
- 1 (or other than 0) for “something went wrong”
This value is used by Keepalived to take action. Scripts are defined like this in /etc/keepalived.conf:
vrrp_script check_sip {
script "/etc/keepalived/checksip.sh"
interval 5 # check every 5 seconds
fall 2 # require 2 failures for KO
rise 4 # require 4 successes for OK
}As you can see in the example, it’s possible to specify the interval in seconds and also how many times the script needs to succeed or fail until any action is taken.
The script can check anything you want. Here are some ideas:
- Is the daemon X running?
- Is the interface X on the remote switch Y up?
- Is the IP 8.8.8.8 pingable?
- Is there enough disk space available to run my application?
- $MYIDEA
Check out the Check Script Configuration Samples section on how to do some of those.
Create /etc/keepalived/checksip.sh and make sure it is executable.
#!/bin/bash
if ls /etc/keepalived/MASTER; then
timeout 1 sipsak -s sip:s@10.10.10.10:5060
exit
else
exit 0
fiThis script will test SIP service on Kamailio’s private IP and make sure Kamailio is working on the Master node. I will explain how I use the /etc/keepalived/master-backup.sh to determine the master node in a little bit.
Notify Script
A notify script can be used to take other actions, not only removing or adding an IP to an interface. It can trigger any script you desire based on . And this is how it can be defined in the Keepalived configuration:
vrrp_instance MyVRRPInstance {
[...]
notify_master "/etc/keepalived/master-backup.sh MASTER"
notify_backup "/etc/keepalived/master-backup.sh BACKUP"
notify_fault "/etc/keepalived/master-backup.sh FAULT
}- notify_mater – is triggered when the node becomes a master node.
- nofity_backup – is triggered when the node becomes a backup node.
- notify_fault – is triggered when VRRP determine the network is at fault or when one of your check script has reached its fault threshold.
So with the above setting, we want to create the script in /etc/keepalived/master-backup.sh and make it executable:
#!/bin/bash
STATE=$1
NOW=$(date +"%D %T")
KEEPALIVED="/etc/keepalived"
case $STATE in
"MASTER") touch $KEEPALIVED/MASTER
echo "$NOW Becoming MASTER" >> $KEEPALIVED/COUNTER
/etc/init.d/Kamailio start
exit 0
;;
"BACKUP") rm $KEEPALIVED/MASTER
echo "$NOW Becoming BACKUP" >> $KEEPALIVED/COUNTER
/etc/init.d/Kamailio stop || killall -9 Kamailio
exit 0
;;
"FAULT") rm $KEEPALIVED/MASTER
echo "$NOW Becoming FAULT" >> $KEEPALIVED/COUNTER
/etc/init.d/Kamailio stop || killall -9 Kamailio
exit 0
;;
*) echo "unknown state"
echo "$NOW Becoming UNKOWN" >> $KEEPALIVED/COUNTER
exit 1
;;
esacWe rely on this script to start or stop Kamailio server. The reason I am not running active-active Kamailio HA is because is because if the backup Kamailio is running and sending probing to its load balancing targets, it will generate good amount of VIP errors continuous in the syslog file for the VIP it does not own yet.
I rather have a cleaner log file that I can use to troubleshoot later and sacrifice a few seconds waiting for the backup Kamailio to start.
Boot Sequence
As I mentioned, we don’t want Kamailio to start on boot on its own. We want Keepalived to manage the start and stop of Kamailio application. Here is how we disable Kamailio on boot:
update-rc.d -f Kamailio removeThe boot system on Ubuntu is currently messed up. Some application use Upstart and some application still use System V, there is no telling which upstart managed application will start first. But if you are using MySQL as the database for Kamailio, you will want to ensure MySQL is started before Kamailio. And because we are using Keepalived to control Kamailio, therefore we want MySQL to start before Keepalived when boot:
Disable Keepalived from starting via System V
update-rc.d -f keepalived removeCreate an Upstart script in /etc/init/keepalived.conf that will start Keepalived service after MySql server is started on boot:
# Keepalived Service
description "Keepalived"
start on started mysql
pre-start script
/etc/init.d/keepalived start
end script
post-stop script
/etc/init.d/keepalived stop
end scriptRestart Keepalived on both nodes when you are ready to :
service keepalived restartCheck Script Configuration Samples
Showcase different ways to check services:
vrrp_script chk_sshd {
script "killall -0 sshd" # cheaper than pidof
interval 2 # check every 2 seconds
weight -4 # default prio: -4 if KO
fall 2 # require 2 failures for KO
rise 2 # require 2 successes for OK
}
vrrp_script chk_haproxy {
script "killall -0 haproxy" # cheaper than pidof
interval 2 # check every 2 seconds
}
vrrp_script chk_http_port {
script "</dev/tcp/127.0.0.1/80" # connects and exits
interval 1 # check every second
weight -2 # default prio: -2 if connect fails
}
vrrp_script chk_https_port {
script "</dev/tcp/127.0.0.1/443"
interval 1
weight -2
}
vrrp_script chk_smtp_port {
script "</dev/tcp/127.0.0.1/25"
interval 1
weight -2
}How to incorporate the above checks into vrrp_instance configs:
vrrp_instance VI_1 {
interface eth0
state MASTER
virtual_router_id 51
priority 100
virtual_ipaddress {
192.168.200.18/25
}
track_interface {
eth1 weight 2 # prio = +2 if UP
eth2 weight -2 # prio = -2 if DOWN
eth3 # no weight, fault if down
}
track_script {
chk_sshd # use default weight from the script
chk_haproxy weight 2 # +2 if process is present
chk_http_port
chk_https_port
chk_smtp_port
}
}
vrrp_instance VI_2 {
interface eth1
state MASTER
virtual_router_id 52
priority 100
virtual_ipaddress {
192.168.201.18/26
}
track_interface {
eth0 weight 2 # prio = +2 if UP
eth2 weight -2 # prio = -2 if DOWN
eth3 # no weight, fault if down
}
track_script {
chk_haproxy weight 2
chk_http_port
chk_https_port
chk_smtp_port
}
}For every set of VIPs, use a new vrrp_instance profile with unique instance name and virtual_router_id number. track_interface is optional for checking network interfaces, it will mark FAULT state if any of the interface goes down.
Monitoring with OMD or Check_MK
Ah ha, I knew you would ask. This section will come out later.
TCP Failover?
I have done my share of research work to find a solution to safely migrate established TCP connection from master node to backup node without success. It will be so cool to have SIP TCP session to stay alive during the failover. Even so, I am keeping my notes here for people who would like to give it a stab.
All the following effort seemed like working when I check the TCP session after failover but when I actually trying to verify the session, it fails. If anyone of you know anything that works, please do share with us in the comment section.